Caractères et encodages
Savez-vous ce qu'est un caractère, un codage de caractères, la différence entre un octet et un caractère, où se situe l'ASCII ? Si ce n'est pas le cas, surtout à l'ère de l'internationalisation et de l'Unicode, ou quand on vous parle de base 64, vous avez sans doute du mal. Je souhaitais donc revenir dessus dans cet article, afin de tenter de rendre tout ça un peu plus clair.
C'est quoi un caractère ?
Tout d'abord, la grosse notion à absorber est celle de caractère. Il s'agit de l'unité atomique (la plus petite, on ne peut pas aller en-dessous) du texte, et d'une notion qui descend de la typographie. J'aurais bien du mal à vous expliquer de quoi il s'agit, donc prenons directement des exemples : la lettre « A », le chiffre « 5 » ou encore le signe de ponctuation « . » sont des caractères. Ces caractères sont associés à une représentation graphique, ou du moins à ce à quoi ils doivent ressembler en gros. De ces instructions généralistes, il y a plusieurs façons de les représenter exactement, et ça, ce sont les polices de caractère qui s'en occupent. Par exemple, voici ce à quoi ressemble le caractère « a » sous différentes polices de caractères :
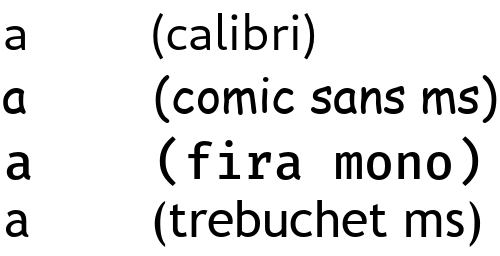
Comme vous pouvez le voir, bien que les lettres sont différentes, elles se ressemblent : il s'agit d'un rond avec un trait qui dépasse en haut et se rabat vers la gauche.
Ces caractères-là constituent ce qu'on appelle des « caractères affichables ». Il en existe d'autres, qui diffèrent complètement dans leur principe mais qu'on a quand même englobé dans la notion de caractère, il s'agit de la notion de caractères de contrôles. Ceux-là ne disent pas à l'afficheur (votre navigateur web, votre terminal, etc) d'afficher quelque chose, ils lui disent de faire quelque chose. Le caractère de contrôle le plus simple et le plus répandu est le retour à la ligne, qu'on représente souvent sous la forme « \n ». Ce caractère dit à ce qui le lit « va à la ligne ».
Tables de caractères
Sauf que voilà, le concept de caractère est bien sympathique, mais l'ordinateur, lui, ne comprend que des nombres. Qu'à cela ne tienne, nous n'avons qu'à associer un nombre à chaque caractère, en définissant ainsi ce qu'on appelle une table de caractères. Tenez, par exemple, la lettre « A ». Quel nombre souhaitez-vous lui associer ?
« 65 ! » répond l'ASCII. « 65 aussi », répond l'Unicode. « 193 » répond l'EBCDIC (ancien encodage d'IBM). « 65 chez moi », répond Windows-1252.
Comme vous pouvez le constater, tout le monde n'est pas d'accord, même si beaucoup reprennent l'ASCII, qui est, encore aujourd'hui, mondialement connu et utilisé. Sauf que voilà, ça se gâte pour les caractères qui ne sont pas américains. Par exemple, quel nombre associer au caractère « € » ?
« 164 ! » répond l'ISO-8859-16 (Latin-10). « 128 ! » répond Windows-1252. « 8364 ! » répond l'Unicode. « 219 ! » répond Mac OS Roman. « 159 ! » répond l'EBCDIC 297.
Et encore, je ne compte pas tous les encodages (plus ou moins anciens, d'ailleurs) qui ont juste haussé les épaules, dont l'ASCII, pour dire qu'ils ne connaissent pas ce caractère. Autant dire que c'est un sacré bazar !
Dans le cadre cet article, nous poserons notre propre table de caractères pour représenter les caractères dont nous avons besoin : disons qu'on associe 1 au caractère « 1 », 2 au caractère « 2 », ainsi de suite jusqu'à 9 pour le caractère « 9 », 10 pour le caractère « 0 », 11 pour le caractère « A », 12 pour le caractère « B » et ainsi de suite jusqu'à 36 pour le caractère « Z ».
En suivant ce codage, je peux maintenant dire que le mot « COUCOU » correspond à la séquence de nombres 13 25 31 13 25 31 ! Attention, nous n'avons pas encore défini la façon dont nous allions poser cette séquence dans la mémoire de l'ordinateur, ce que nous allons faire juste après.
Organisation en une séquence de chiffres binaires (codage sur des « bits »)
Sauf qu'il s'agit d'une vérité inexacte que de dire que l'ordinateur comprend des nombres : en réalité, l'ordinateur raisonne sur des chiffres binaires, communément appelés bits (pour « binary digits »). Il raisonne même en général sur des groupes de ces chiffres, ce qu'on appelle des bytes. Aujourd'hui, on considère que ces bytes font 8 bits, c'est pourquoi on les appelle des octets en français.
L'idée est donc de poser notre séquence de nombres sur une séquence d'octets, d'une façon ou d'une autre : c'est la notion d'encodage. Attention, certains standards ne définissent qu'une table de caractères (quel nombre correspond à quel caractère), certains standards ne définissent que la façon d'encoder les caractères, et les autres définissent les deux. L'ASCII par exemple définit à la fois la table et l'encodage, alors que l'Unicode ne définit que la table de caractères (on note d'ailleurs les caractères Unicode en U+<code hexadécimal du caractère>, par exemple U+0020 pour l'espace), et l'UTF-8 ne définit que l'encodage à partir des caractères définis par l'Unicode.
Reprenons notre exemple, avec notre table de caractères à nous. Afin de faciliter le traitement par les ordinateurs d'aujourd'hui, on va utiliser une technique toute bête également utilisée par l'ASCII : stocker un code correspondant à un caractère par octet. Par exemple, notre message de tout à l'heure, « COUCOU », occupera six octets, pour six caractères, dont le premier contiendra la valeur 13 et le dernier la valeur 31. Pour économiser de la place, comme chaque valeur est entre 0 et 36 (bien que 0 soit une valeur inutilisée), on pourrait n'encoder chaque caractère que sur six bits, et on aurait même eu un peu de place pour rajouter des caractères !
La méthode du « un octet par caractère » pour faire la correspondance entre octets et codes correspondant à des caractères n'est largement pas la seule, il y en a plein adaptées à différents contextes, techniques et historiques. Il existe une myriade de façons différentes de représenter ses caractères Unicode sur un flux d'octets (ou même d'un sous-ensemble de ses caractères), entre l'UCS-2, l'UTF-16, l'UTF-32BE, l'UTF-8, l'UTF-7, et caetera. Parfois ces codages sont à taille fixe, à savoir qu'un octet occupe toujours le même espace, parfois ils sont à taille variable (l'opposé).
Et d'ailleurs, à propos de flux.
Caractères et bits, deux univers différents
Bien que des liens soient établis entre les caractères et les bits, tels que l'encodage pour coder des caractères sur des bits ou encore des codages tels que la base 16 ou la base 64 pour coder des bits sur des caractères, il est très important, à mon sens, de distinguer les deux.
Ainsi, lorsque par exemple, on travaille sur un protocole ou sur un format, l'une des premières choses à se demander concernant le format de ses messages, c'est s'ils sont envoyés et reçus sur un flux de bits/octets ou de caractères. En effet, ce n'est pas la même méthode de lecture et d'écriture pour les deux : pour des caractères, il faut bien penser à lire ou écrire dans l'encodage demandé, ou utiliser les fonctions capables de le faire !
Comment cela se concrétise-t-il ? Par exemple, vous voulez traiter des caractères Unicode, n'importe lesquels, et les encoder en UTF-8 derrière. Vous pouvez raisonner directement en UTF-8, mais la façon propre de le faire est de raisonner en un encodage plus facile à manipuler, comme l'UTF-32 qui utilise une taille fixe pour tous les caractères, puis, une fois le traitement terminé, de convertir en UTF-8 pour la transmission ou le stockage dans le fichier. Sous des systèmes de type UNIX, en C, pour éviter d'avoir à faire cette conversion soi-même, on trouve des interfaces pour gérer ça, comme wchar.h ou iconv, ou encore des bibliothèques comme utf8proc.
Conclusion
J'espère que dans cet article, vous aurez compris un peu plus ce qu'est un caractère, une table de caractères et un encodage. Dans un futur article, je reviendrai sur les encodages liés à l'Unicode qui sont le produit de hacks super ingénieux.